理解 MVC / Model2 / MVP / MVVM / Flux
总结一下目前流行的MV*设计模式,着重其在前端环境的应用问题。
传统MVC
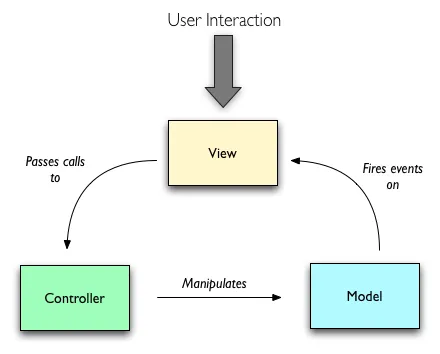
可以看到传统的MVC的设计,让Model的变化能迅速的反应在view的变化上。如果和下面的model2 模式相比,我认为传统的MVC模式是更加适用于视图会长时间存在并且需要频繁跟随数据变化的场景,比如传统的客户端程序,web前端页面。
有人说Backbone用了传统的MVC,其实不然。Backbone和传统的MVC的区别在于,它的view直接去操纵model了,因此它几乎没有controller(它的C只用来处理route的变化了)
Model2
Model2也是MVC的一种,其架构如图:
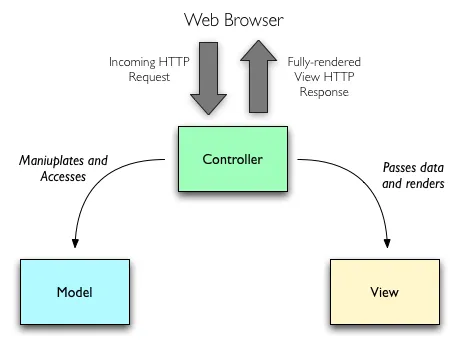
和传统MVC相比,它的主要区别在于Model和View的完全隔离,并且C和M与V之间都是单向的。之所以这样的设计,其实很大原因在于它的应用场景主要是在web 服务后端。对于web 服务后端的角度来说,控制器接受到的事件来源很统一,绝大部分是网络请求,而网络请求的结果就是一个view的render,再加上HTTP本身无状态的特质,每一个view之间都是独立而短暂的,任何需要反映出model的变化,都需要产生一个新的view。
因此在这样的场景下,Model2的架构中,model的变化不需要反馈给controller,因为服务端不需要主动推送变化给浏览器中的view。同时View本身也不需要将自己的事件直接反馈给后端。(实际上这些大部分事件都是在浏览器中被前端架构中的控制器来处理,然后部分以网络请求的方式反馈给后端,但是那时反馈回来的view就是一个新的view了)
MVP 和 MVVM
MVP(Model-View-Presenter)和MVVM(Model-View-ViewModel)都是传统MVC的变种,在满足传统MVC可以让Model迅速反馈到View中的同时,更好的隔离Model和View。
- Model和View不直接关联到一起
- Presenter和ViewModel监听model的变化,来更新view
核心介绍一下MVP和MVVM的区别。
MVP
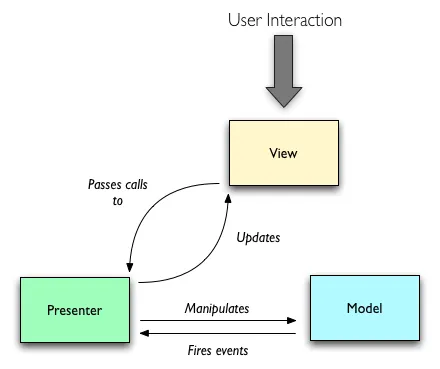
在MVP中,View自己实现如何进行视图更新的实现细节,并抽象出一层视图接口,而Presenter在model更新后,通过调用这些接口来实现View的更新。同时Presenter也向View注册相关的需要Presenter来决定的视图事件。如:
// 视图发生了变化
Mode.on( ‘change’, function( m ){
Presenter.getView().updateView( m );
});
// Presenter 在某些情况下对Model进行更新
Presenter.getView().on( ‘someEvent’, function( someData ){
Model.update( someData );
});MVVM
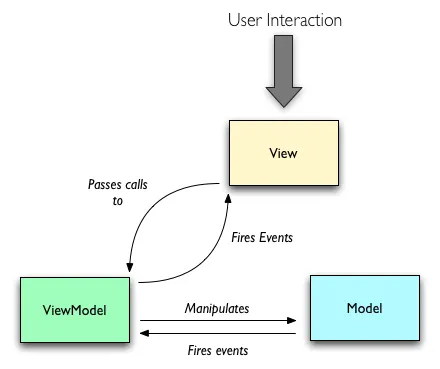
MVVM区别于MVP的核心点在于ViewModel更新View的方式。MVVM的技术基础在于,需要有一套机制实现View和ViewModel的数据绑定,这意味着ViewModel上的变化会实时的体现到View的更新上,而View上的一些事件变化也会直接改变ViewModel的值。在ViewModel和Model的关系上,和Presenter和Model的关系是类似的。
关于ViewModel,我的理解是,它更像是在Model层抽离出来的一层专门为UI服务的model层。MVVM模式通过ViewModel和View的这种双向绑定的机制替代了MVP模式中P和V的手动桥接,从而使得View的逻辑更加简单,甚至成为固定形态的状态机,而ViewModel这一层的逻辑加重,如何设计ViewModel的数据结构成为一个重点。
如此看来,MVP和MVVM是比较适合web前端开发的设计模式,但是以上两种架构的模式介绍中对于真实的前端场景还是有一个不同于后端服务的地方,因为前端的“事件”不仅仅是view层的用户交互事件,还可能有:
- 用户的URL变化
- 网络请求的回调
- 其他一些事件响应(如传感器)
那么为了处理这些非View相关的事件,可能又要在这个模式之上额外添加一个类似Controller的角色。这个角色在接收到这些事件后去修改Model,然后通过Model变化间接更新View。
另外对于MVP或者MVVM模式而言,如果一个View的变化会间接影响其他View的话,那么这个数据流可能是这样的:
用户交互了View -> View通知ViewModel -> ViewModel去修改Model -> Model变化通知相关的所有ViewModel -> ViewModel更新所有相关的View这可能是比较简单的情况,在交互和数据都很复杂的场景下,有可能会出现这样的级联变化:
用户交互了View -> View通知ViewModel -> ViewModel去修改Model -> Model变化通知相关的所有ViewModel -> ViewModel更新所有相关的View -> 部分被更新的View产生事件通知对应的ViewModel -> ViewModel去修改Model -> 又产生新的更新流...以上的级联更新在真实场景中是难以避免的,这里举出这个例子不是说这是MVVM或者MVP造成的问题,而是用这两种模式会造成这个链条在一个线性节点链上折返往复:
A -> B -> C -> B -> A -> B -> C -> ..一旦这个链接变长,从最后的结果上,很难判断触发的根源位置。
所以总结一下,虽然MVP和MVVM在前端的场景下已经可以实现M和V很好的分离,以及实现M和V的快速响应,但是依旧存在:
- 无法统一抽象前端中类型繁多的事件
- 其数据流在遇到级联更新时会产生折返路径,从而造成难以定位问题根源
于是,为了解决这两个问题,FLUX就出现。
Flux
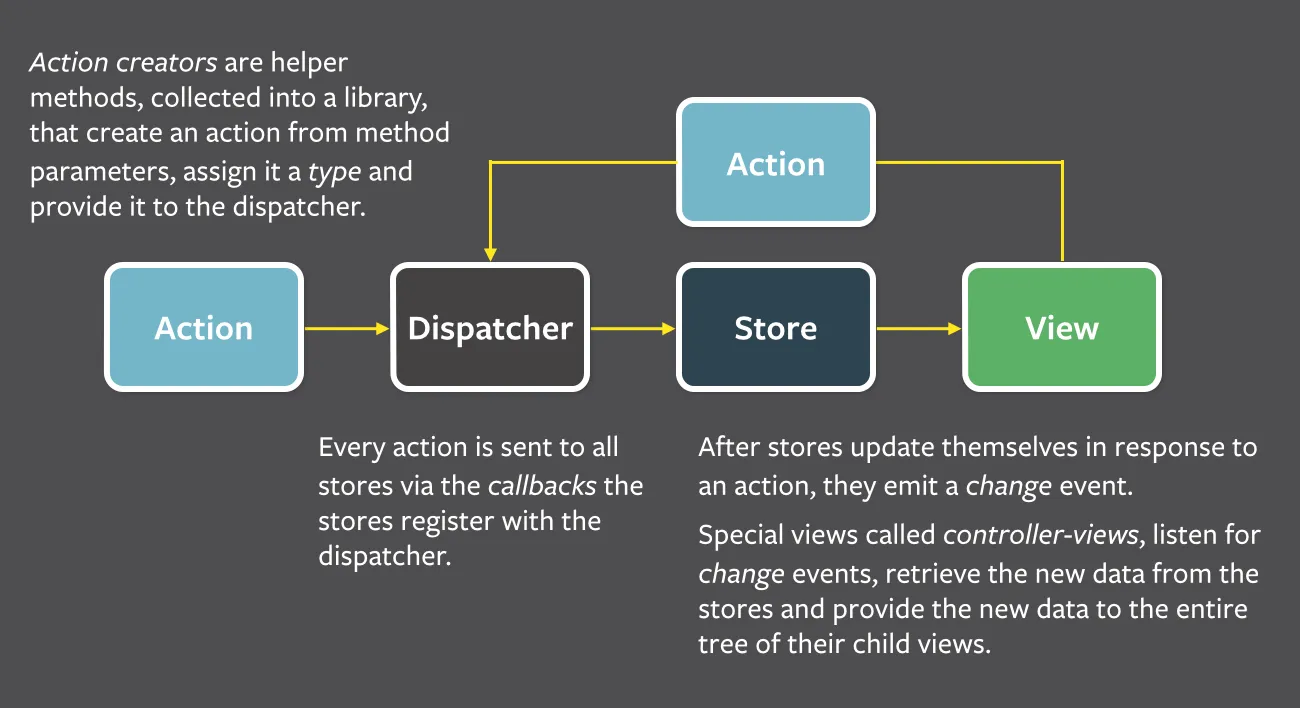
谈到Flux就必须先说ReactJS。ReactJS是MV*吗?
官方的说法是,ReactJS认为自己只是MV*中的V的角色,而且事实上我也赞同这种说法,我们看一下ReactJS的两个重要特点:
- ShadowDOM,这一点让ReactJS有很好的性能,以及跨平台渲染的能力。这点完全和View如何渲染有关
- 它的组件定义模式,其实是侧重于纯粹的状态机型的View的模式,它的render方法和setState的设计,都是以这个为核心。而这个特点也是完全为了view的渲染服务的。
换个角度说,利用React的DeepLink,可以很方便的实现一套数据双向绑定,来实现MVVM;如果让组件本身提供很多对外接口,也能很方便的实现一个MVP。因此我认为ReactJS是一个专注于View层的库。所以在讨论FLUX时,仅仅将ReactJS作为其中View层渲染方式的部分来进行讨论。
回到Flux上来,如上图所示,为了方便比较,我们拿MVP和FLUX进行类比:
- Store:就是MVP中的Model
- View:MVP中的view部分。FLUX中的VIEW更加依赖ReactJS的这种渲染机制
- Controller-Views:FLUX的结构中没有很明确的这个角色,其实就是从Store中拿了数据进行View渲染的上层View,其角色和Presenter是有点类似的,但是仅仅局限于Presenter更新View的过程
Flux和MVP不同的地方:
- 类似Presenter角色的Controller-Views只更新View,而不会反向去接受View的事件去更新store(也就是Model)
- FLUX统一了所有的“事件”,不管是View的用户交互事件,还是View无关的事件,比如URL变更,比如传感器,比如网络请求事件。
由于Flux中的Controller-View并不负责处理View的事件并修改Model,因此不会产生折返显现,也就是实现了“单向数据流”:
View变化 -> 产生Action -> Store被更新 -> View更新虽然也会出现级联View更新:
View变化 -> 产生Action -> Store被更新 -> View更新变化 -> 产生新的Action -> Store被更新 -> View更新变化但是由于不存在折返,其路径比MVP和MVVM短,更加容易追溯根源。同时由于有了统一的Action,每一次的变化都有记录可以查询。
于是通过FLUX这种架构,我们实现在前端架构中需要的:
- Model(Store)和View的分离
- Model(Store)和View的快速更新
- 统一了所有的前端“事件”
- 单向数据流,数据路径更加清晰
然而Flux依旧存在一些问题(其实更多的是官方实现上的细节问题):
- 扁平而繁多的Store造成了dispatch的时候调度的复杂度,甚至还有waitFor这种方法来构建调度依赖。
- Store的分离造成了跨Store的数据处理上的难度,强行跨Store引用本身又反模式
于是Flux之后出现了大热的Redux,虽然Redux声称自己不是一种Flux的实现,然后我还是觉得它是Flux的一种实现,只是比官方的实现更加更好而已:
- 单独的State。解决了Flux官方实现中上面提到的问题
- Reducer以及immutable state的方案,让数据层的业务逻辑更加独立和灵活,其实完全可以理解为后端的“中间件”概念。同时由于reducer的简单定义和函数性编程特点,又使得Redux可以很好的支持hot reload
参考:
- http://stackoverflow.com/questions/32461229/why-use-redux-over-facebook-flux
- http://blog.nodejitsu.com/scaling-isomorphic-javascript-code
- http://facebook.github.io/react/index.html
- http://www.christianalfoni.com/articles/2015\_08\_02\_Why-we-are-doing-MVC-and-FLUX-wrong
- http://redux.js.org/
- https://facebook.github.io/flux/docs/overview.html
- http://www.roypeled.com/an-mvp-guide-to-javascript-model-view-presenter/
Comments